import requests
from bs4 import BeautifulSoup
import pandas as pd
import warnings
warnings.filterwarnings('ignore', message='not allowed')Introduction to Sentiment Analysis in Legal Texts
Welcome to this tutorial on sentiment analysis within the legal domain. This tutorial aims to guide you through the essential steps of collecting, processing, and analyzing legal texts using modern NLP techniques. We focus on aspect-based sentiment analysis, which involves identifying specific aspects of legal texts and understanding the sentiment expressed towards these aspects.
Data Scraping
Data scraping involves programmatically gathering data from internet sources. In this tutorial, we start by scraping legal documents from publicly available law databases. We use Python’s requests library to fetch the data and BeautifulSoup to parse the HTML content, allowing us to extract meaningful information efficiently.
# URL of the legal document
url = 'https://static.case.law/md-app/1/html/0001-01.html'
# Fetch the HTML content
response = requests.get(url)
html_content = response.text
# Parse the HTML content
soup = BeautifulSoup(html_content, 'html.parser')# Extract data using BeautifulSoup based on the classes
case_title = soup.find('h4', class_='parties').get_text(separator=" ", strip=True)
docket_number = soup.find('p', class_='docketnumber').get_text(strip=True)
decision_date = soup.find('p', class_='decisiondate').get_text(strip=True)
judges_involved = soup.find('p', class_='judges').get_text(strip=True)
court_opinion = soup.find('p', class_='author').find_next('p').get_text(strip=True)
# Extract all paragraphs of legal text
legal_texts = [p.get_text(" ", strip=True) for p in soup.find_all('p')[1:]]
# Compile extracted data into a DataFrame
data = {
'Case Title': [case_title],
'Docket Number': [docket_number],
'Decision Date': [decision_date],
'Judges Involved': [judges_involved],
'Court Opinion': [court_opinion],
'Legal Texts': ["\n\n".join(legal_texts)]
}
df = pd.DataFrame(data)print(df['Legal Texts'][0])Initial Term, 1967.]
Decided February 2, 1967.
*2 Before Anderson, Morton, Orth and Thompson, JJ.
Morton, J.,
delivered the opinion of the Court.
This is an application for leave to appeal from a denial of post conviction relief by Judge Charles D. Harris in the Criminal Court of Baltimore on January 17, 1966.
Applicant, represented by Court appointed counsel, pleaded guilty on January 17, 1949 to four indictments of robbery with a deadly weapon and was sentenced to four consecutive twenty year terms in the Maryland State Penitentiary. No appeal was taken from the conviction and sentence.
Applicant’s petition under the Post Conviction Procedure Act was filed on December 7, 1965. Counsel was appointed to represent him and a hearing was held on January 4, 1966. At that time, applicant advanced but one contention, viz.:
At the hearing before Judge Harris, petitioner affirmed the fact that his guilty pleas were voluntarily made and that he understood what he was doing when he entered such pleas. He further testified that his real purpose in initiating his actioir for post conviction relief was to obtain a reduction in his eighty year sentence.
It is, of course, well settled that a guilty plea, freely and intelligently made, operates of itself as a conviction of the highest order and constitutes a waiver of all nonjurisdictional defects, and Judge Harris so held in denying the petition. See Frazier v. Warden, 243 Md. 676 (1966); Treadway v. War *3 den, 243 Md. 680 (1966) ; Campbell v. Warden, 240 Md. 729 (1965). Equally well settled is the fact that where the sentence imposed by the court was within statutory limits, it is not a matter for review under the Act. Nash v. Warden, 243 Md. 700 (1966); Davis v. Warden, 235 Md. 637 (1964).
In his memorandum in support of his application for leave to appeal, the applicant suggests that while the consecutive sentences may not have been unlawful, combined they were grossly and inordinately disproportionate to the offenses committed, and hence excessive, cruel and unusual as to be in violation of the Maryland Declaration of Rights and the Eighth Amendment to the Federal Constitution. In Mitchell v. State, 82 Md. 527 (1896) it was held that where the punishment is grossly disproportionate to the offense so that the sentence is evidently dictated not by a sense of public duty, but by passion, prejudice, ill-will or any other unworthy motive, the judgment ought to be reversed and the cause remanded for a more just sentence. Although Mitchell continues to be the law of Maryland, applicant does not seriously contend that the trial judge, in passing sentence, was actuated by prejudice or similar improper motive. While this contention is not properly before us, not having been directly raised below, nevertheless we find nothing in the record before us to indicate that the sentence in question was in any manner unconstitutional. See Roberts v. Warden, 242 Md. 459 (1966) and Gleaton v. State, 235 Md. 271 (1964).
Application denied.# URL of the directory listing page
url = 'https://static.case.law/md-app/1/html/'
# Make the request
response = requests.get(url)
html_content = response.text
# Parse the HTML
soup = BeautifulSoup(html_content, 'html.parser')
file_links = [a['href'] for a in soup.find_all('a') if a['href'].endswith('.html')]
print(file_links)['https://static.case.law/md-app/1/html/0001-01.html', 'https://static.case.law/md-app/1/html/0003-01.html', 'https://static.case.law/md-app/1/html/0008-01.html', 'https://static.case.law/md-app/1/html/0010-01.html', 'https://static.case.law/md-app/1/html/0014-01.html', 'https://static.case.law/md-app/1/html/0018-01.html', 'https://static.case.law/md-app/1/html/0021-01.html', 'https://static.case.law/md-app/1/html/0023-01.html', 'https://static.case.law/md-app/1/html/0025-01.html', 'https://static.case.law/md-app/1/html/0030-01.html', 'https://static.case.law/md-app/1/html/0038-01.html', 'https://static.case.law/md-app/1/html/0043-01.html', 'https://static.case.law/md-app/1/html/0046-01.html', 'https://static.case.law/md-app/1/html/0056-01.html', 'https://static.case.law/md-app/1/html/0061-01.html', 'https://static.case.law/md-app/1/html/0065-01.html', 'https://static.case.law/md-app/1/html/0069-01.html', 'https://static.case.law/md-app/1/html/0074-01.html', 'https://static.case.law/md-app/1/html/0081-01.html', 'https://static.case.law/md-app/1/html/0085-01.html', 'https://static.case.law/md-app/1/html/0094-01.html', 'https://static.case.law/md-app/1/html/0098-01.html', 'https://static.case.law/md-app/1/html/0108-01.html', 'https://static.case.law/md-app/1/html/0123-01.html', 'https://static.case.law/md-app/1/html/0127-01.html', 'https://static.case.law/md-app/1/html/0132-01.html', 'https://static.case.law/md-app/1/html/0136-01.html', 'https://static.case.law/md-app/1/html/0139-01.html', 'https://static.case.law/md-app/1/html/0147-01.html', 'https://static.case.law/md-app/1/html/0154-01.html', 'https://static.case.law/md-app/1/html/0161-01.html', 'https://static.case.law/md-app/1/html/0173-01.html', 'https://static.case.law/md-app/1/html/0178-01.html', 'https://static.case.law/md-app/1/html/0190-01.html', 'https://static.case.law/md-app/1/html/0200-01.html', 'https://static.case.law/md-app/1/html/0205-01.html', 'https://static.case.law/md-app/1/html/0213-01.html', 'https://static.case.law/md-app/1/html/0217-01.html', 'https://static.case.law/md-app/1/html/0222-01.html', 'https://static.case.law/md-app/1/html/0233-01.html', 'https://static.case.law/md-app/1/html/0239-01.html', 'https://static.case.law/md-app/1/html/0243-01.html', 'https://static.case.law/md-app/1/html/0249-01.html', 'https://static.case.law/md-app/1/html/0253-01.html', 'https://static.case.law/md-app/1/html/0256-01.html', 'https://static.case.law/md-app/1/html/0264-01.html', 'https://static.case.law/md-app/1/html/0270-01.html', 'https://static.case.law/md-app/1/html/0276-01.html', 'https://static.case.law/md-app/1/html/0281-01.html', 'https://static.case.law/md-app/1/html/0286-01.html', 'https://static.case.law/md-app/1/html/0292-01.html', 'https://static.case.law/md-app/1/html/0297-01.html', 'https://static.case.law/md-app/1/html/0304-01.html', 'https://static.case.law/md-app/1/html/0309-01.html', 'https://static.case.law/md-app/1/html/0318-01.html', 'https://static.case.law/md-app/1/html/0324-01.html', 'https://static.case.law/md-app/1/html/0326-01.html', 'https://static.case.law/md-app/1/html/0342-01.html', 'https://static.case.law/md-app/1/html/0347-01.html', 'https://static.case.law/md-app/1/html/0353-01.html', 'https://static.case.law/md-app/1/html/0358-01.html', 'https://static.case.law/md-app/1/html/0362-01.html', 'https://static.case.law/md-app/1/html/0373-01.html', 'https://static.case.law/md-app/1/html/0379-01.html', 'https://static.case.law/md-app/1/html/0383-01.html', 'https://static.case.law/md-app/1/html/0389-01.html', 'https://static.case.law/md-app/1/html/0392-01.html', 'https://static.case.law/md-app/1/html/0396-01.html', 'https://static.case.law/md-app/1/html/0399-01.html', 'https://static.case.law/md-app/1/html/0406-01.html', 'https://static.case.law/md-app/1/html/0418-01.html', 'https://static.case.law/md-app/1/html/0423-01.html', 'https://static.case.law/md-app/1/html/0433-01.html', 'https://static.case.law/md-app/1/html/0441-01.html', 'https://static.case.law/md-app/1/html/0444-01.html', 'https://static.case.law/md-app/1/html/0448-01.html', 'https://static.case.law/md-app/1/html/0450-01.html', 'https://static.case.law/md-app/1/html/0455-01.html', 'https://static.case.law/md-app/1/html/0469-01.html', 'https://static.case.law/md-app/1/html/0474-01.html', 'https://static.case.law/md-app/1/html/0478-01.html', 'https://static.case.law/md-app/1/html/0481-01.html', 'https://static.case.law/md-app/1/html/0495-01.html', 'https://static.case.law/md-app/1/html/0500-01.html', 'https://static.case.law/md-app/1/html/0505-01.html', 'https://static.case.law/md-app/1/html/0511-01.html', 'https://static.case.law/md-app/1/html/0520-01.html', 'https://static.case.law/md-app/1/html/0522-01.html', 'https://static.case.law/md-app/1/html/0528-01.html', 'https://static.case.law/md-app/1/html/0534-01.html', 'https://static.case.law/md-app/1/html/0537-01.html', 'https://static.case.law/md-app/1/html/0540-01.html', 'https://static.case.law/md-app/1/html/0548-01.html', 'https://static.case.law/md-app/1/html/0556-01.html', 'https://static.case.law/md-app/1/html/0564-01.html', 'https://static.case.law/md-app/1/html/0569-01.html', 'https://static.case.law/md-app/1/html/0571-01.html', 'https://static.case.law/md-app/1/html/0576-01.html', 'https://static.case.law/md-app/1/html/0578-01.html', 'https://static.case.law/md-app/1/html/0581-01.html', 'https://static.case.law/md-app/1/html/0586-01.html', 'https://static.case.law/md-app/1/html/0591-01.html', 'https://static.case.law/md-app/1/html/0605-01.html', 'https://static.case.law/md-app/1/html/0623-01.html', 'https://static.case.law/md-app/1/html/0627-01.html', 'https://static.case.law/md-app/1/html/0630-01.html', 'https://static.case.law/md-app/1/html/0647-01.html', 'https://static.case.law/md-app/1/html/0653-01.html', 'https://static.case.law/md-app/1/html/0657-01.html', 'https://static.case.law/md-app/1/html/0662-01.html', 'https://static.case.law/md-app/1/html/0664-01.html', 'https://static.case.law/md-app/1/html/0666-01.html', 'https://static.case.law/md-app/1/html/0670-01.html', 'https://static.case.law/md-app/1/html/0674-01.html', 'https://static.case.law/md-app/1/html/0678-01.html', 'https://static.case.law/md-app/1/html/0681-01.html']def extract_information(html_content):
# Parse the content with BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
# Extract various elements safely
case_title = soup.find('h4', class_='parties')
docket_number = soup.find('p', class_='docketnumber')
decision_date = soup.find('p', class_='decisiondate')
judges_involved = soup.find('p', class_='judges')
court_opinion = soup.find('p', class_='author')
# Use get_text if element exists, else use a default value
case_title_text = case_title.get_text(separator=" ", strip=True) if case_title else "Title Not Found"
docket_number_text = docket_number.get_text(strip=True) if docket_number else "Docket Number Not Found"
decision_date_text = decision_date.get_text(strip=True) if decision_date else "Decision Date Not Found"
judges_involved_text = judges_involved.get_text(strip=True) if judges_involved else "Judges Involved Not Found"
court_opinion_text = court_opinion.find_next('p').get_text(strip=True) if court_opinion and court_opinion.find_next('p') else "Court Opinion Not Found"
legal_texts = "\n\n".join([p.get_text(" ", strip=True) for p in soup.find_all('p')]) if soup.find_all('p') else "Legal Texts Not Found"
return {
'Case Title': case_title_text,
'Docket Number': docket_number_text,
'Decision Date': decision_date_text,
'Judges Involved': judges_involved_text,
'Court Opinion': court_opinion_text,
'Legal Texts': legal_texts
}
# DataFrame to store all cases information
cases_data = [] # Use a list to collect data
# Loop through each file link and extract data
for file_url in file_links:
response = requests.get(file_url)
if response.status_code == 200:
case_info = extract_information(response.text)
cases_data.append(case_info) # Append dictionary to list
else:
print(f"Failed to download {file_url}")
# Convert the list of dictionaries to a DataFrame once after the loop
all_cases_df = pd.DataFrame(cases_data)Data Cleaning
Once data is scraped, the next crucial step is data cleaning. This involves removing irrelevant information, correcting formatting issues, and preparing the text for analysis. Techniques such as tokenization, removal of stopwords, and normalization are used to ensure that the data is clean and standardized.
Feature Engineering and Clustering
Feature engineering is a critical process where specific features are extracted from the text to aid in the analysis. For legal texts, features like the presence of specific legal terms or citations can be crucial. Clustering is then applied to group similar documents, which helps in identifying common themes or topics within the corpus. We employ algorithms like KMeans for clustering, and PCA for reducing dimensionality and visualizing the data clusters.
Aspect and Location-Aware Sentiment Analysis
In legal documents, the sentiment might not only be general but also specific to certain aspects or locations within the text. Aspect-based sentiment analysis focuses on understanding sentiments expressed towards specific facets of the document. We enhance this by incorporating location-aware models that consider where within the document sentiments are expressed, using advanced techniques like BERT and other transformer-based models for nuanced understanding.
import nltk
import re
nltk.download('punkt')
nltk.download('stopwords')
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
stop_words = set(stopwords.words('english'))all_cases_df['Legal Texts Cleaned'] = all_cases_df['Legal Texts'].apply(lambda x: re.sub(r'[\[\]\n]', ' ', x))
all_cases_df['Legal Texts Tokenized'] = all_cases_df['Legal Texts Cleaned'].apply(word_tokenize)#!pip install spacyall_cases_df.to_csv('MD_Vol1.csv', index=False)
# df = pd.read_csv('MD_Vol1.csv')from collections import Counter
import matplotlib.pyplot as plt
all_words = [
word for opinion in all_cases_df['Court Opinion']
for word in word_tokenize(opinion.lower())
if word not in stop_words and word.isalpha()
]
# Count frequencies
word_counts = Counter(all_words)
# Prepare plot
word_df = pd.DataFrame(word_counts.items(), columns=['Word', 'Frequency']).sort_values(by='Frequency', ascending=False).head(20)
plt.figure(figsize=(10, 8))
plt.barh(word_df['Word'], word_df['Frequency'], color='skyblue')
plt.xlabel('Frequency')
plt.title('Top Words in Court Opinion')
plt.gca().invert_yaxis() # Highest frequencies on top
plt.show()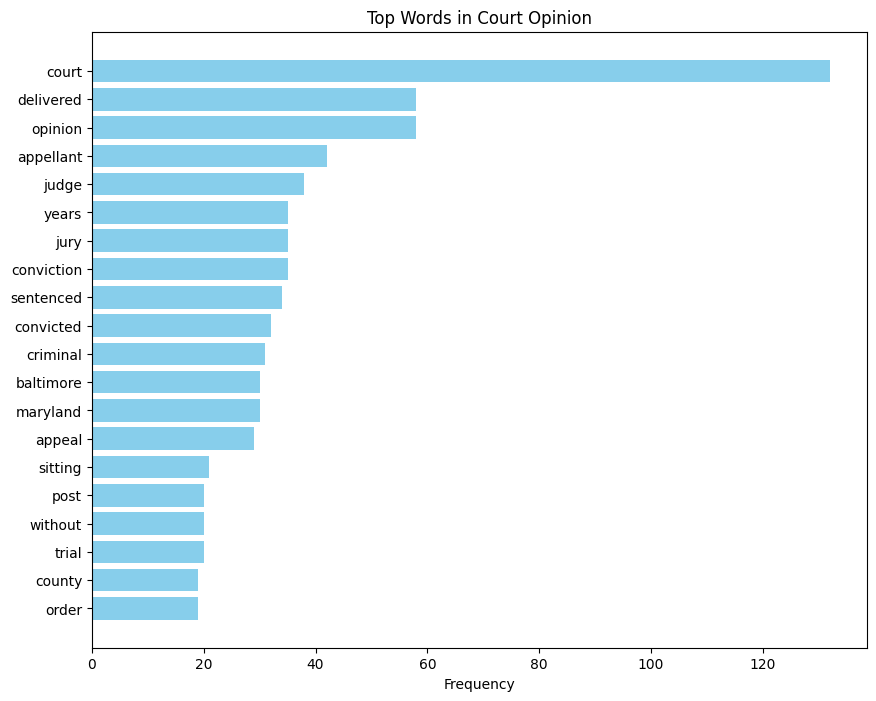
Context-Aware Modeling
Context-aware modeling involves understanding the broader context of sentiments expressed in legal texts. This is crucial for legal documents where the context can significantly influence the interpretation. Techniques such as Graph Neural Networks (GNNs) are introduced to capture the relationships and interdependencies among various components of the legal texts.
import spacy
# !python -m spacy download en_core_web_trf
nlp = spacy.load("en_core_web_trf")# Example sentence
example_sentence = all_cases_df['Court Opinion'][104]
doc = nlp(example_sentence)
# Extract aspects and opinions
aspects = []
opinions = []
for token in doc:
if token.dep_ == 'amod' and token.head.pos_ == 'NOUN':
aspects.append(token.head.text)
opinions.append(token.text)
print("Aspects:", aspects)
print("Opinions:", opinions)Aspects: ['larceny', 'goods', 'count']
Opinions: ['grand', 'stolen', 'second']from spacy import displacy
# Render the dependency parse to an SVG
svg = displacy.render(doc, style='dep', jupyter=False)
# Save the SVG to a file
svg_path = "/content/dependency_parse.svg"
with open(svg_path, "w", encoding="utf-8") as file:
file.write(svg)#!pip install cairosvg
!cairosvg /content/dependency_parse.svg -d 200 -o /content/dependency_parse.png
from IPython.display import Image, display
# Display the image
display(Image(filename='/content/dependency_parse.png'))
# Function to clean text
def clean_text(text):
tokens = word_tokenize(text.lower()) # Tokenize and lowercase
filtered_tokens = [word for word in tokens if word.isalpha() and word not in stop_words] # Remove punctuation and stopwords
return ' '.join(filtered_tokens)
# Apply the cleaning function
all_cases_df['Cleaned Court Opinions'] = all_cases_df['Court Opinion'].apply(clean_text)from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(all_cases_df['Cleaned Court Opinions'])from sklearn.cluster import KMeans
# Choosing a k-value (for example, 5 clusters) and fit K-means
k = 3
kmeans = KMeans(n_clusters=k, random_state=0)
kmeans.fit(X)
# Assign the cluster labels back to the DataFrame
all_cases_df['Cluster'] = kmeans.labels_
# Define cluster names based on your analysis or top words
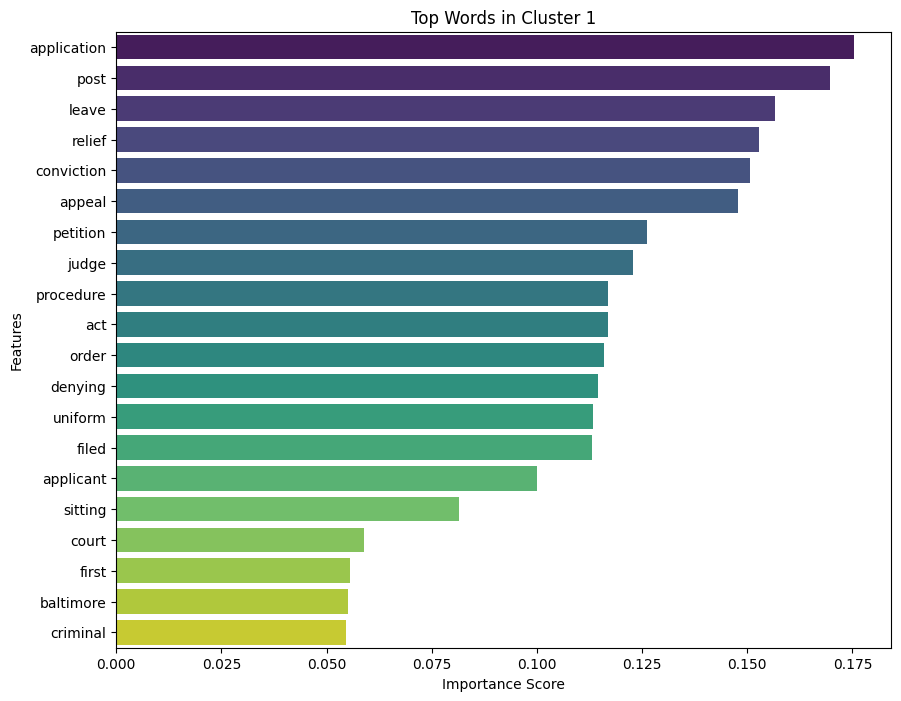
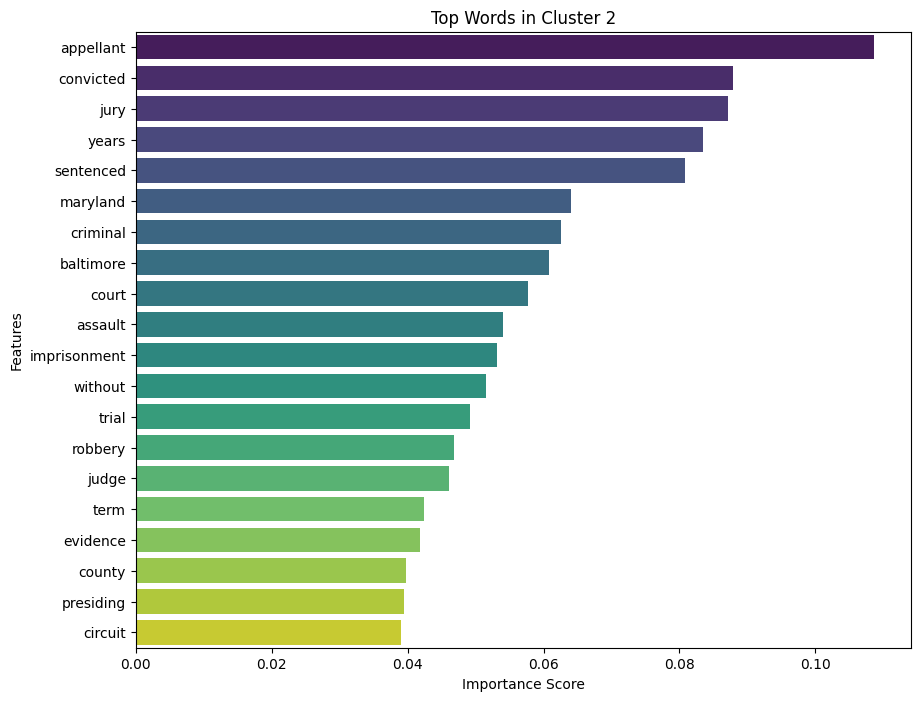
cluster_names = {
0: "Opinion Delivered Court",
1: "Application Leave Appeal Denying",
2: "Appellant Convicted Jury Sentenced"
}
# Map the cluster labels to names
all_cases_df['Cluster Name'] = all_cases_df['Cluster'].map(cluster_names)import numpy as np
def get_top_features_cluster(tfidf_array, prediction, n_feats):
labels = np.unique(prediction)
dfs = []
for label in labels:
id_temp = np.where(prediction == label)
x_means = np.mean(tfidf_array[id_temp], axis = 0)
sorted_means = np.argsort(x_means)[::-1][:n_feats]
features = vectorizer.get_feature_names_out()
best_features = [(features[i], x_means[i]) for i in sorted_means]
df = pd.DataFrame(best_features, columns = ['features', 'score'])
dfs.append(df)
return dfs
# Get top features for each cluster
dfs = get_top_features_cluster(X.toarray(), kmeans.labels_, 20)
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
def plot_top_features(dfs):
for i, df in enumerate(dfs):
plt.figure(figsize=(10, 8))
sns.barplot(data=df, x='score', y='features', hue='features', dodge=False, palette='viridis', legend=False)
plt.title(f'Top Words in Cluster {i}')
plt.xlabel('Importance Score')
plt.ylabel('Features')
plt.legend().remove()
plt.show()plot_top_features(dfs)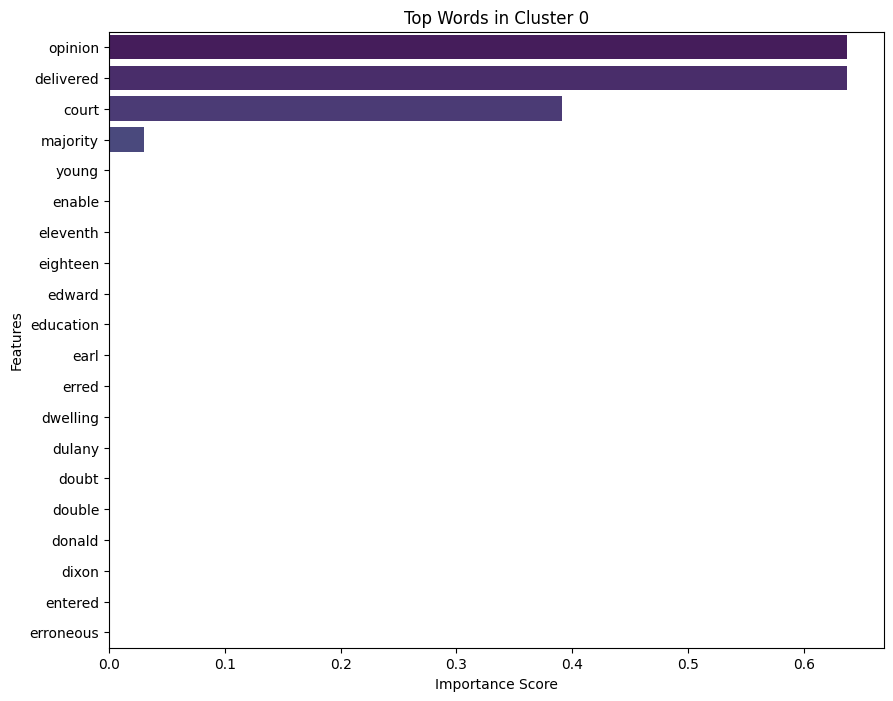
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import numpy as np
# Reduce dimensions for visualization
pca = PCA(n_components=3)
scatter_plot_points = pca.fit_transform(X.toarray())
colors = ['r', 'b', 'g']
fig = plt.figure(figsize=(18, 12))
ax = fig.add_subplot(111, projection='3d')
# Calculate centroids for annotations in 3D
centroids = np.array([scatter_plot_points[kmeans.labels_ == i].mean(axis=0) for i in range(3)])
top_words = ["opinion delivered court", "application leave appeal denying", "appellant convicted jury sentenced"] # Example top words from clusters
# Plot each cluster with its points and annotate
for i in range(3):
points = np.array([scatter_plot_points[j] for j in range(len(scatter_plot_points)) if kmeans.labels_[j] == i])
ax.scatter(points[:, 0], points[:, 1], points[:, 2], s=30, c=colors[i], label=f'Cluster {i}')
ax.text(centroids[i][0], centroids[i][1], centroids[i][2], top_words[i], fontsize=12, weight='bold', ha='center')
# Set labels for each axis corresponding to the principal components
ax.set_xlabel('PCA 1')
ax.set_ylabel('PCA 2')
ax.set_zlabel('PCA 3')
ax.legend()
plt.title('3D Cluster Plot of Court Opinions')
plt.show()
Conclusion
This tutorial provided a comprehensive foundation in handling, processing, and analyzing legal texts with a focus on sentiment analysis. By following the steps outlined, you can build robust NLP applications that are capable of understanding complex legal narratives and aid in legal analytics.